Below are all formulas and calculations we go through when recommending sample sizes and determining significance.
How we ensure distribution of people
For every experiment, we leverage PostHog's multivariate feature flags. There's one control group, and up to three test groups. Based on their distinctID, each user is randomly distributed into one of these groups. This is stable, so the same users, even when they revisit your page, stay in the same group.
We do this by creating a hash out of the feature flag key and the distinct ID. It's worth noting that when you have low data (<1,000 users per variant), the difference in variant exposure can be up to 20%. This means, a test variant could have 800 people only, when control has 1,000.
All our calculations take this exposure into account.
Recommendations for sample size and running time
When you're creating an experiment, we show you recommended running times and sample sizes based on parameters you've chosen.
For trend experiments, we use Lehr's equation as explained here to determine sample sizes.
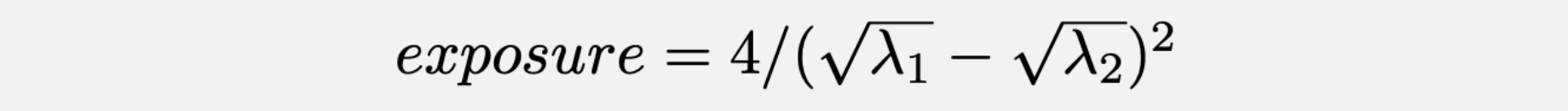

where lambda1 is the baseline count data we've seen for the past two weeks,
and lambda2 is baseline count + mde*(baseline count).
mde is the minimum acceptable improvement you choose in the UI.
For funnel experiments, we use the general Sample Size Determination formula, with 80% power and 5% significance. The formula then becomes:


where mde is again the minimum detectable effect chosen in the UI.
We give these values as an estimate for how long to run the experiment. It's possible to end experiments before you reach the end, if you see an outsized effect.
Note how the recommended sample size in each case is inversely related to the minimum acceptable improvement. This makes sense, since the smaller the mde, the more sensitive your experiment is, and the more data you need to judge significance.
Bayesian A/B testing
We follow a mostly bayesian approach to A/B testing. While running any experiment, we calculate two parameters: (1) Probability of each variant being the best, and (2) whether the results are significant or not.
Below are calculations for each kind of experiment.
Trend experiment calculations
Trend experiments capture count data. For example, if you want to measure the change in total count of clicks, you'd use this kind of experiment.
We use Monte Carlo simulations to determine the probability of each variant being the best. Every variant can be simulated as a gamma distribution with shape parameter = trend count, and exposure = relative exposure for this variant.
Then, for each variant, we can sample from their distributions and get a count value for each of them.
The probability of a variant being the best is given by:
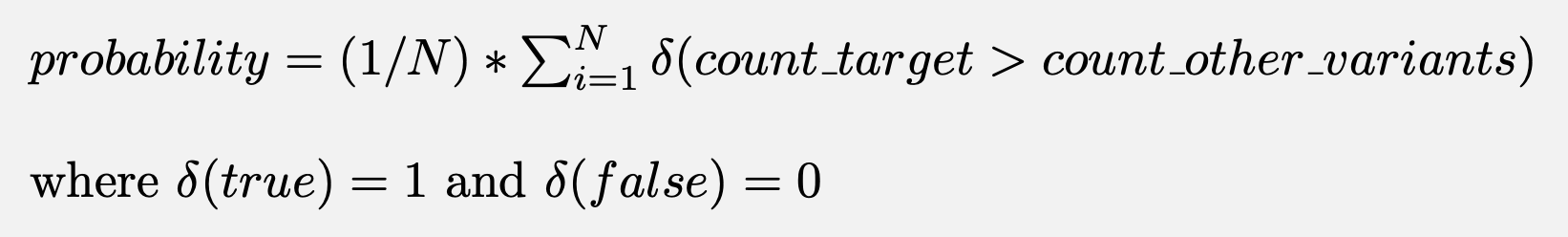
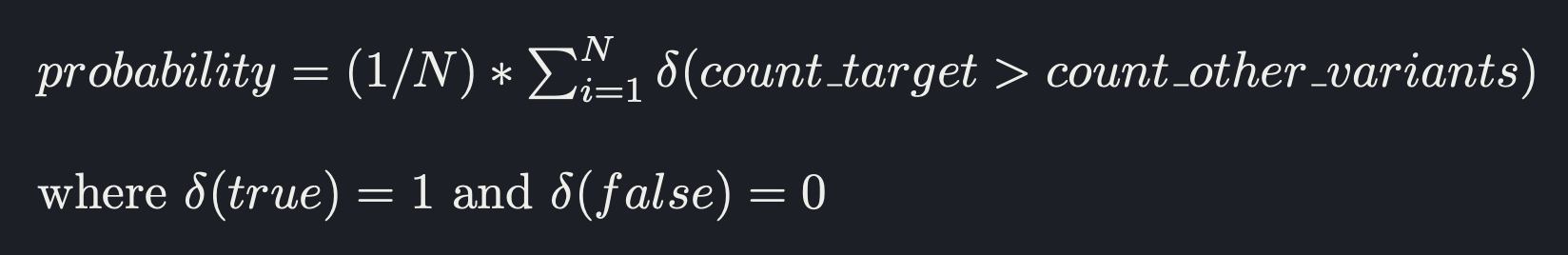
For calculating significance, we currently measure p-values using a poisson means test. Here's a good primer of the formula. Results are significant when the p-value is less than 0.05
Trend experiment exposure
Since count data can be over a total count, vs. the number of unique users, we use a proxy metric to measure exposure: The number of times $feature_flag_called event returns control or test is the respective exposure for the variant. This event is sent automatically when you do: posthog.getFeatureFlag().
It's possible that a variant showing fewer count data can have higher probability, if its exposure is much smaller as well.
Funnel experiment calculations
Funnel experiments capture conversion rates. For example, if you want to measure the change in conversion rate for buying a subscription to your site, you'd use this kind of experiment.
We use monte carlo simulations to determine the probability of each variant being the best. Every variant can be simulated as a beta distribution with alpha parameter = number of conversions, and beta parameter = number of failures, for this variant.
Then, for each variant, we can sample from their distributions and get a conversion rate for each of them.
The probability of a variant being the best is given by:

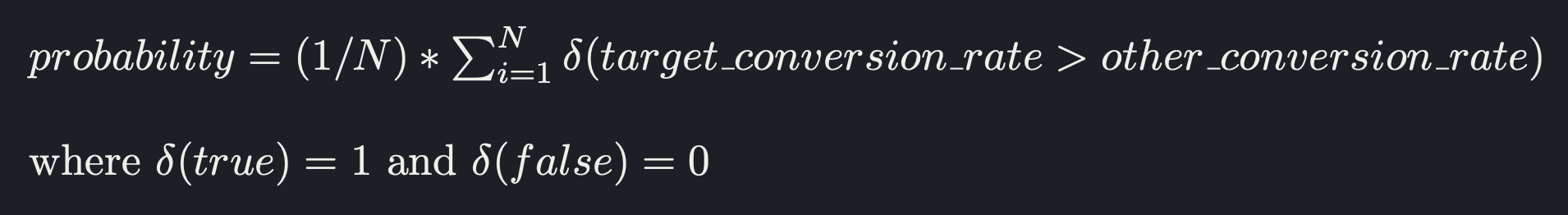
To calculate significance, we calculate the expected loss, as first mentioned in VWO's SmartStats whitepaper.
To do this, we again run a monte carlo simulation, and calculate loss as:
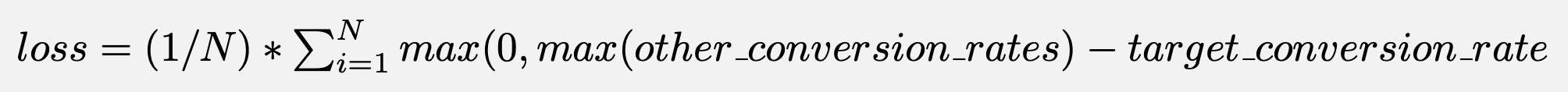

This represents the expected loss in conversion rate if you chose any other variant. If this is below 1%, we declare results as significant.
How do we handle statistical significance?
For your results and conclusions to be valid, any experiment must have a significant exposure. For instance, if you test a product change and only one user sees the change, you can't extrapolate from that single user that the change will be beneficial/detrimental for your entire user base. This is true for any experiment that is a simple randomized controlled experiment (e.g. this is also done when testing new drugs or vaccines).
Furthermore, even a large sample size (e.g. approx. 10,000 participants) can result in ambiguous results. If, for example, the difference in conversion rate between the variants is less than 1%, it's hard to say whether one variant is truly better than the other. To be significant, there must be enough difference between the conversion rates, given the exposure size.
PostHog computes this significance for you automatically - we will let you know if your experiment has reached significant results or not. Once your experiment reaches significant results, it's safe to use those results to reach a conclusion and terminate the experiment.
In the early days of an experiment, data can vary wildly, and sometimes one variant can seem overwhelmingly better. In this case, our significance calculations might say that the results are significant, but this shouldn't be the case, since we need more data.
Thus, before we hit 100 participants for each variant in an experiment, we default to results being not significant. Further, if the probability of the winning variant is less than 90%, we default to results being not significant.
So, you'll only see the green significance banner when all 3 conditions are met:
- Each variant has >100 unique users
- The calculations above declare significance
- The probability of being the best > 90%.